
I have always been particularly impressed with the forecasting performance of the Prophet model. It has only a few parts: seasonality, holidays, any external regressors, and with those it has some of the most consistent forecasting performance around. Also, being a linear model (with Bayesian parameter estimation), Prophet offers a decomposable explainability/interpretability, i.e. Monday has n% impact vs Friday. Prophet isn’t unique, such linear models have been around for ages, but it seems to have really captured the core elements well while being easily accessible.
However, Prophet has a few major flaws. The biggest, in my opinion, is the trend. By default, the trend forecast is essentially an average value naïve of the trend since the last changepoint. This has caused all sorts of problems using it at work because it doesn’t deal with ‘bubbles’, a surge in growth followed by a collapse or vice-versa, like many companies saw during covid, easily. It also is slow, especially for a linear model. Running it on hundreds or thousands of models gets to be a drag (although this has been improved a bit recently). Prophet also lacks support for other common forecasting inputs, in particular autoregressive lags.
In addition to these basic fixes, I wanted to add more. I wanted to directly incorporate the features of an tool called AMFM which includes two features: trend dampening and product impacts/goaling. I also wanted to incorporate my large library of preprocessing in AutoTS more directly into the model, as well as onto more of the model inputs. Then I also wanted to make the model multivariate to a certain extent by adding multivariate feature options and by allowing holiday countries and regressors to be specified on a per-series basis.
Oh, and I also wanted to add in my automatic anomaly detection, with options to model anomalies separately. I also wanted to add in the automatic holiday detection I have built as well. I also wanted this packaged in a nice to use package with standard interface, and with plotting and user specifications like model constraints. Overall goals: interpretability and accuracy.
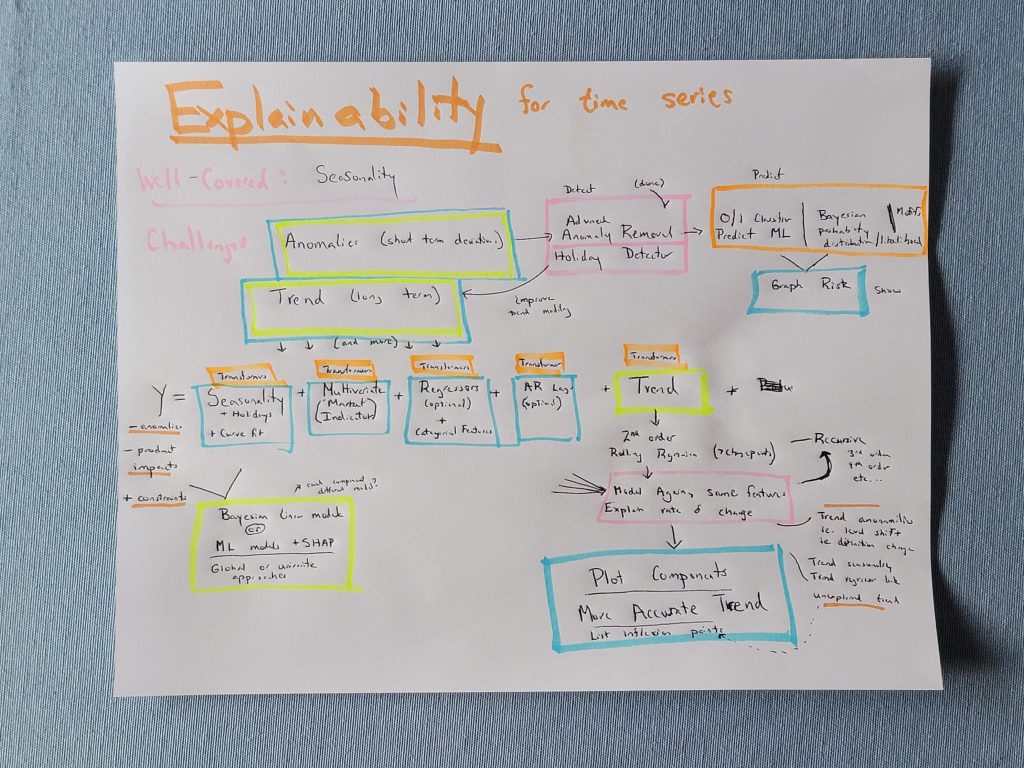
Figure 1 Brainstorming notes for Cassandra
I think it is safe to say that no such alternative model exists because this has tons of moving, often conflicting pieces that turning it into a generalizable framework is an immense effort. It took me around 2 months of full-time work to build the beta version of Cassandra, and that was already having a vast majority of the code and functions already written into AutoTS. Even with that time, a few pieces are missing that I desired. The model doesn’t yet have a Bayesian estimation option, the anomaly future modeling is barely implemented, and the multivariate feature creation is functional but much less extensive than planned. These may come later. There are also still a few bugs for a few parameter combinations, although the greatest part now seems to be stable.
However, from the high level the Cassandra code is all pretty simple. The model begins with some preprocessing and detection. It then constructs an X array of the specified features. This X array is used with a linear model (usually but not limited to least squares) to predict as much as it can, with a placeholder in the place of the trend component. The result Y is then subtracted from the actuals and this residual is then given a local linear trend. Trend_window determines the smoothing of this trend. Small values, like 3, are essentially the raw residuals, while larger values, like 365, lose some detail but more clearly show the long-term trend. Preprocessing and anomaly detection are performed on this trend, then the trend model (any AutoTS model) generates the forecast of the trend component. Trend forecast and linear components are added together for the final forecast.
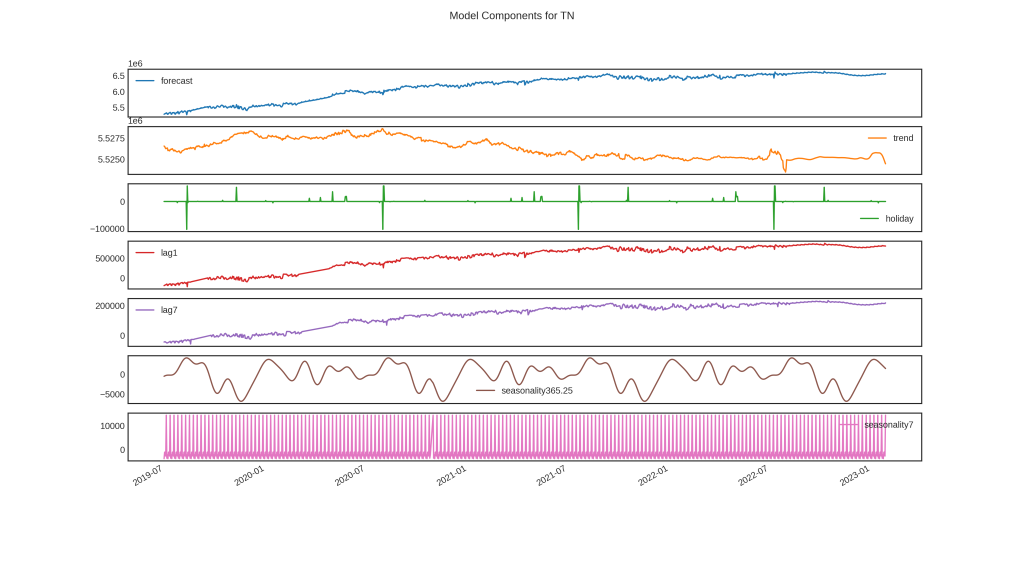
Figure 2: Cassandra Components, a good forecast but showing an AR lag asserting Trend due to constant growth of series
Behind the scenes, there are a couple of possible ‘for’ loops that can happen. If AR lags are used, then it must loop step by step of the forecast length. If any unique per series X features are used (such as regr_per_series, but other features as well) then it must loop through each individual series present. Both of these loops are relatively fast, but do explain why some parameter combinations will be rather slow and others very fast.
One problem I have seen is that autoregressive features (AR1, etc) can and will learn the trend if there is a constant trend present in the series, as shown in the figure above. Specifying a detrend preprocessing or avoiding AR params in this case can help. My overall experience so far suggests AR features usually improve accuracy, but reduce the interpretability slightly.
Another theoretical problem is that the trend model, because it can be a quite sophisticated model, can compensate for the linear model extremely well. So far, I have only seen this help, where the trend model adds nuance the linear model wasn’t capable of adding. However, it is possible that the trend model somewhat contradicts the linear model, making the model more difficult to interpret. That should not impact accuracy on a good model, just interpretability.
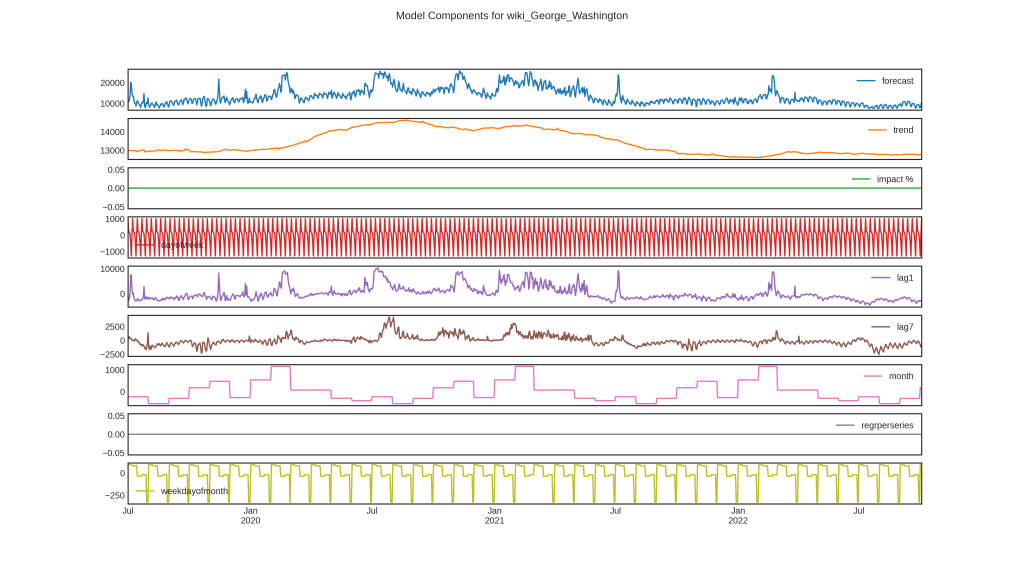
And just one more note, seasonality can be specified both by a binarized date part, as well as by a numeric fourier order. Hence why ‘dayofweek’ and ‘seasonality7’ can both be seen as similar, but not identical options in the graphs. A third option, “commonfourier” is an auto-detected seasonality, and while it has several fourier components, all are combined into one subplot of the components.
I compared the accuracy of Cassandra to Prophet on a dataset containing 5 years of daily data composed of over 200 different series representing different geographic regions. I used AutoTS to run 3 validation evaluations on forecast lengths of half a year. AutoTS’s preprocessing was turned off (max_transformer_depth=0), so models were on their own with the raw data. I ran over 500 generations of genetic optimization which tunes all of the available parameters for both models. This searched the entire breadth of Prophet parameters available but didn’t cover all of Cassandra’s, which has a massive possible feature space, but still covered many thousands of combinations. Accordingly, the final results may not be the absolute best, but they should be pretty close to the model’s maximal performance.
One thing to note is that AutoTS’s implementation of Prophet includes a feature I added, automatic holiday detection, and this functionality was used in all of the best models. It looks to have added about a 15% performance improvement on overall Score on this dataset compared to the next best models without. Performance outside of AutoTS may be slightly lower as a result. Prophet here is also parallelized, running on 12 jobs (of a 16 core/32 thread machine Ryzen 5900X). No external regressors were used, and holiday_countries were not provided (as Prophet in AutoTS doesn’t have a comparable way to Cassandra of passing uniquely specified country for each series). Nor was any ensembling used, just finding the best ‘one size fits all’ model for the given series.
I optimized on a mix of metrics as AutoTS does, generating a normalized Score. This seeks an overall best, well-balanced model. However, if you were only concerned with optimizing on one metric, it is likely that the results could be optimized a bit further than what is shown here, at the cost of losing accuracy on other objectives.
Two metrics immediately jump out across all the model runs. The first is runtime. The average Cassandra model ran in 1 second or less. The average Prophet model took 85 seconds to run. I was expecting this improvement, but what I was not expecting was the massive jump in SPL (scaled pinball loss) performance. To be honest, I was expecting the Bayesian Prophet model to beat Cassandra on this metric, however here the average validated Cassandra model had an SPL of 3.5 and the average Prophet model was in the 10-20 range. Lower is better in both cases, and these are truly stunning improvements.
| Model | Cassandra | Prophet |
| Validations | 3 | 3 |
| smape | 3.839347 | 5.093178 |
| mae | 164615 | 228975.5 |
| rmse | 194255.7 | 282496.7 |
| spl | 3.557528 | 20.68754 |
| contour | 0.710147 | 0.642483 |
| max error | 528276.1 | 735812.4 |
Here is side-by-side of best Cassandra vs best Prophet model, averaged across 3 validations and all 200+ time series. Best performance is in bold. Both models did well, but Cassandra outperformed Prophet by a significant margin on all metrics. This particular Prophet model, while best on most metrics, was not the best of the Prophet models for SPL.
One thing to note is that Cassandra responded much more to parameter tuning than Prophet. Out of the box with simple configurations, they are quite similar. Cassandra, however, simply has many more options which allow more specificity to a particular dataset. Prophet is mostly limited to tuning the hyperpriors.
For all models, accuracy decreased as length of training data history decreased. There was a significant difference between models run on 5 years of history and those run on only 2 years of history. It is difficult to say what the optimal amount of data history is, but somewhere in the range of 5 – 10 years should be the goal. This is highly dependent on data, so ignore this if it doesn’t match with your own experience.
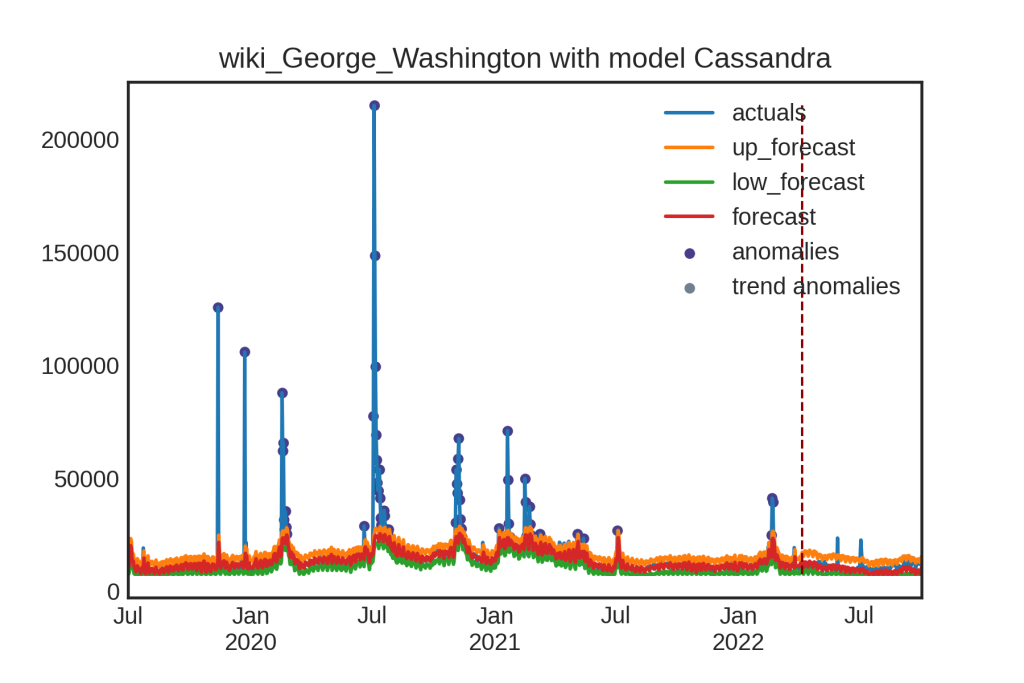
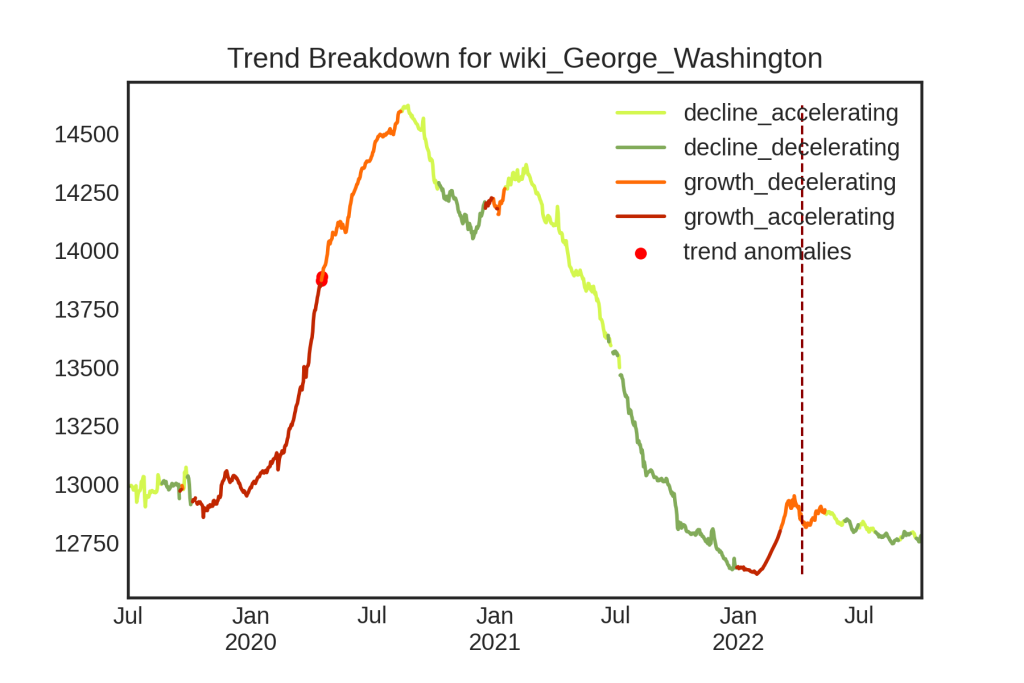
Below are graphs of Cassandra run on a different, open-source dataset of Wikipedia page views. Here, there is a trend, but not a constant trend, accordingly the AR parts do not take over the trend. This also showcases the plot_trend trend breakdown graph with anomaly detection run on the trend as well as on the original series. This data does a much better job of showcasing the in-built anomaly detection options.
One challenge with Cassandra is simply finding the right parameters to run. This is made easier by a function of the model class called get_new_params which will randomly generate new parameters to try. Sample code is viewable in the bottom of the autots.models.cassandra.py file of AutoTS.
This article may appear in an identical or modified form shared by my employer Nousot.