
It has been impossible in the past to get all three of the largest neural network architectures running in the same Python environment in such a way that they don’t conflict and so that they will also train on GPU.
The reason I want all the libraries running in the same environment is that AutoTS has a collection of models that include models utilizing all of Tensorflow, MXNet, and PyTorch. I want to be able to utilize and compare all of these approaches, since each of the models are unique with different strengths. If only one library needs to be used at once, often the simplest approach is to download one of the prebuilt containers available that already has done all the hard work already.
The first solution is to install the CPU versions of all of the libraries, or only one library with GPU training enabled. This actually a decent approach. As we shall see below, the CPU training of neural nets on a good CPU is competitive in runtime with GPUs.
But, if you have already sunk a small fortune into a GPU, it would be nice to utilize it anyway. The underlying problem is that all of the binaries for these packages depend on different versions of Nvidia’s CUDA.
Start with a computer that already has Nvidia graphics drivers installed and recently updated. On Linux, running the nvidia-smi command will show driver and GPU usage details. These days, CUDA seems to be packaged into defaults, as I found that version 11.6 was automatically installed. Unfortunately, that version is too new as the libraries usually depend on CUDA versions that are a year or two old.
The following was done on a workstation with Ubuntu 22.04 running on an AMD 5950X and RTX 3060 graphics card. This should also work in WSL Linux on Windows. This will not work on Macs, which have something called Apple Metal to accelerate, which on my last trial use was extremely slow and buggy. I am using Mamba here as it is faster than Conda, but all of the mamba commands can be replaced by the conda command with the -c conda-forge option added. I spent a while trying to get cuda configured using the official installation instructions, but in the end the conda/mamba approach worked much better.
This worked on versions tensorflow==2.9.1, mxnet-cu112==1.9.1, torch==1.11.0+cu113 and other packages latest as of June 2022.
mamba activate base
mamba install -c conda-forge cudatoolkit=11.2 cudnn=8.1.0 nccl # install in conda base
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$CONDA_PREFIX/lib/ # NOT PERMANENT
mamba create -n gpu python=3.8 scikit-learn pandas statsmodels prophet numexpr bottleneck tqdm holidays lightgbm matplotlib requests -c conda-forge
mamba activate gpu
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
pip install mxnet-cu112 --no-deps
pip install gluonts tensorflow neuralprophet pytorch-lightning pytorch-forecastingThe approach here is to install CUDA 11.2 in the base environment using conda and point the environmental variable LD_LIBRARY_PATH at that base CUDA. export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/colin/mambaforge/lib in my case. Remember that environmental variables are not permanently set unless specified in a file like .bashrc. LD_LIBRARY_PATH will also effect other libraries like BLAS and SQL drivers, so you may need to make sure those are properly installed in the target path as well (install numpy with conda there to set BLAS).
The exact locations don’t matter, as long as the collection of CUDA and CuDNN libraries files are in the library paths for the environment being used – you could just copy and paste the cuda libraries to whatever library paths you want to use.
I also found it worked better if all the neural network architectures were then installed using pip instead of conda. I think this is because conda would attempt to reinstall different versions of the cuda libs, creating problems. The torch version is for CUDA 11.3, but as far as I can tell it is running on 11.2 without issue. All of the libraries print messages about where they are running, so keep an eye on the logs as they are generated.
Overall, this approach is simple. Have Nvidia drivers ready. Using versions compiled for as close to the same CUDA versions as possible, use conda to download those cuda/cudnn/nccl libraries and make sure those are on the library path. Then use pip to download the neural network packages themselves.
I should note there is another possible approach entirely: build everything from source manually. However, doing that is a pain.
GPU vs CPU Performance
If you haven’t bought a fancy GPU, I would suggest skipping and instead spending they money on a better CPU. GPU training has a bunch of problems. The first is cost, with GPUs being expensive. The second is vendor lock in, with Nvidia still really the only option in town. There are also seem to be more crashes running GPUs than with CPUs, in my experience. Finally, GPUs are not that much faster, perhaps attributable to the additional memory copies required to get the data there.
I would also advise, if buying a GPU, to spend more money on seeking a higher RAM option. I went with the RTX 3060 as it came with 12 GB of RAM, and that much RAM isn’t seen again until the most expensive SKUs. A lack of RAM will limit training big fancy neural nets, but fewer CUDA cores just leads to being a bit slower. Also, I don’t appear to be stressing the GPU to its potential with what I am running. It usually runs at around 20% utilization, never peaking higher than 50% in my observations.
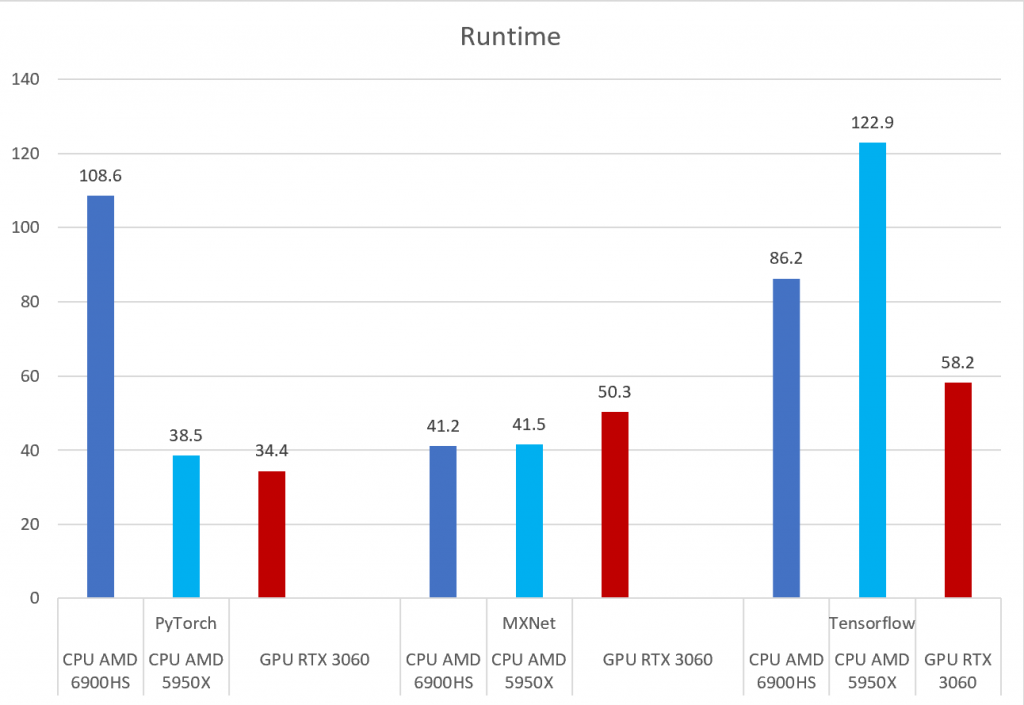
It is interesting to see the runtime results. For MXNet, CPU is faster. My experience with MXNet suggests this library has put the most effort into CPU performance optimization (effective use of BLAS), meaning the extra memory copies for the GPU end up making it slower. For PyTorch and Tensorflow, there is a surprising difference between AMD CPUs. I am fairly certain this is because of the binaries using different BLAS optimizations. For example with Tensorflow on the 6900HS (8 core, 16 thread) it logged that it was using the AVX and AVX2 extensions whereas on the 5950X (16 core, 32 thread) it was built for AVX2 and FMA optimizations. I suspect the FMA usage is why it is slower there, but I have no evidence for that.
For Intel users, there are also Intel CPU optimized versions of Torch and Tensorflow which I had previously tested and also found were faster. I suspect that is just Intel building the binaries with better BLAS support more in line with what MXNet is doing.
Overall, the GPU is the most consistent, but with MXNet faster on CPU, and on Torch with the 5950X very close to the GPU performance, it is hard to justify all the extra software headache and expense of using GPUs in most situations.
Appendix: Test Code on AutoTS 0.4.2
from autots import model_forecast, load_weekly
import timeit
df2 = load_weekly(long=False)
start_time = timeit.default_timer()
forecasts = model_forecast(
model_name="PytorchForecasting",
# model_param_dict={},
model_param_dict={
"model": "TemporalFusionTransformer", "datepart_method": "simple_2", "n_layers": 4, "hidden_size": 64,
},
model_transform_dict={
'fillna': 'rolling_mean',
'transformations': {'0': 'RobustScaler'},
'transformation_params': {'0': {
}}
},
df_train=df2,
forecast_length=14,
return_model=True
)
p_runtime = timeit.default_timer() - start_time
print(f"PytorchForecasting runtime {p_runtime}")
result = forecasts.forecast.head(5)
print(result)
# print(forecasts.model.result_windows.shape)
start_time = timeit.default_timer()
forecasts = model_forecast(
model_name="GluonTS",
# model_param_dict={},
model_param_dict={"gluon_model": "DeepAR", "epochs": 40, "learning_rate": 0.001, "context_length": 10},
model_transform_dict={
'fillna': 'rolling_mean',
'transformations': {'0': 'RobustScaler'},
'transformation_params': {'0': {
}}
},
df_train=df2,
forecast_length=14,
return_model=True
)
g_runtime = timeit.default_timer() - start_time
print(f"GluonTS runtime {g_runtime}")
result = forecasts.forecast.head(5)
print(result)
start_time = timeit.default_timer()
forecasts = model_forecast(
model_name="MultivariateRegression",
model_param_dict={
"regression_model": {
'model': 'KerasRNN',
'model_params': {
'kernel_initializer': 'RandomUniform',
'epochs': 50,
'batch_size': 32,
'optimizer': 'adam',
'loss': 'Huber',
'hidden_layer_sizes': (32, 32, 32),
'rnn_type': 'LSTM',
'shape': 2}}
},
model_transform_dict={
'fillna': 'rolling_mean',
'transformations': {'0': 'StandardScaler'},
'transformation_params': {'0': {
}}
},
df_train=df2,
forecast_length=14,
return_model=False,
fail_on_forecast_nan=True,
)
t_runtime = timeit.default_timer() - start_time
print(f"Tensorflow runtime {t_runtime}")
result = forecasts.forecast.head(5)
print(result)