
If you have no idea what AVX-2 and AVX-512 are, they are names for instruction sets, a combination of CPU design and language that help execute, in this case, math. AVX512 is a newer 512-bit instruction set promising faster performance. Since data science can sometimes be rather slow, faster math sounds very promising.
Overall, the AVX512 instruction were 17% faster overall in this particular test, with individual models seeing 5-20% boost. Some of this was due to slightly improved single-core clockspeeds as well, however (say 2.5% faster) and perhaps other changes in the underlying architecture and execution units. What made this surprisingly difficult is the fastest of all was a laptop CPU (i5 1135) which was offloading instructions to its Xe GPU – and a suggestion that the Desktop CPU was trying to do the same, but with a paltry internal GPU, it was actually slowing itself down as a result.
Normally, we, that is anyone outside the lab of a major CPU designer, wouldn’t really have a chance to compare the differences between these, but enter 11th gen Intel desktop CPUs. These on paper have much of the same specs as their 10th gen predecessors, but feature an entirely new architecture that adds in avx512 instructions. I had a 10700 i7 CPU and with a simple CPU swap, leaving all other components the same, I could test the new 11700 i7 and see what performance differences I saw.
I develop AutoTS, and it happens to provide me a simple way of benchmarking a bunch of different models. I used 200 time series pulled from the M5 competition dataset – 200 series being large enough to run a bunch of models quickly while still giving me some indication of how it performance looks at scale. I ultimately ran 470 models of which 312 ran successfully in all environments.
I setup two virtual environments on the test machines: 1. using OpenBLAS (achieved by a basic pip install) and 2. an Intel-optimized environment installed from the Intel Anaconda channel (instructions in the extended_tutorial). Both of these affect the backends of the computations, primarily the behind-the-scenes work of Numpy and Scikit-learn. Mxnet and GluonTS are an exception here, they used Intel MKL in both environments. OpenBLAS is the only option that properly works on AMD, so it was sole environment on my sole AMD machine. These backends matter quite a lot, as we shall see.
In total, I had the same Desktop, used twice, once with a 10700 CPU and the second time with 11700 CPU. I also had an AMD 4500U powered mini PC and an Intel 1135g7 mini PC – both mobile/laptop chips which aren’t expected to be able to compete with the more powerful desktop 11700 chip. Because the mini PCs have only mediocre cooling, I also ran the 1135g7 outside at 45°F (~ 7°C) for an indication of how it might do with better cooling, it’s suffixed _cold in the results. For the record, the 11700/10700 desktop has an Nvidia GPU, but I had it completely disabled, no CUDA and it’s usage hovered near 1%, confirming it wasn’t in play.
See code here:
https://github.com/winedarksea/autots_benchmark
Abbreviated Results Table:
| 11700intel | 11700openblas | amd4500Uopenblas | 10700intel | 10700openblas | 1135g7openblas | 1135g7intel | FASTEST | |
| Number of Cores | 8 | 8 | 6 | 8 | 8 | 4 | 4 | |
| Boost Clock (GHz) | 4.9 | 4.9 | 4 | 4.8 | 4.8 | 4.2 | 4.2 | |
| Geekbench5 Single | 1732 | 1732 | 1183 | 1325 | 1325 | 1501 | 1501 | |
| Geekbench5 Multi | 9851 | 9851 | 5294 | 9367 | 9367 | 4554 | 4554 | |
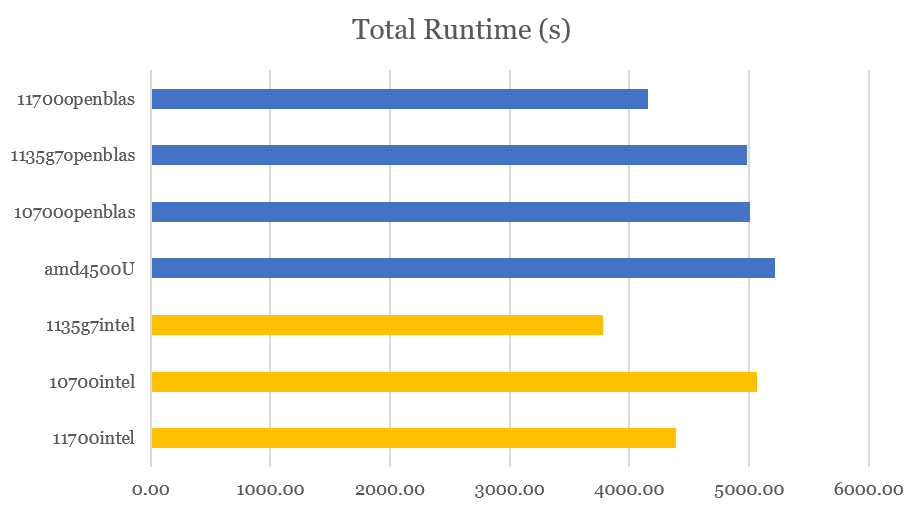
| Total Runtime (s) | 4386.04 | 4151.23 | 5211.82 | 5067.05 | 5003.67 | 4980.50 | 3779.92 | 1135g7intel |
| GLM | 35.93 | 50.57 | 60.08 | 40.80 | 56.62 | 61.66 | 40.36 | 11700intel |
| KNN | 359.99 | 98.67 | 50.96 | 394.99 | 127.80 | 53.67 | 48.56 | 1135g7intel |
| VAR | 83.37 | 79.05 | 37.35 | 86.41 | 81.27 | 39.67 | 22.11 | 1135g7intel |
| AverageValueNaive | 38.13 | 113.65 | 88.21 | 38.73 | 119.94 | 118.38 | 36.44 | 1135g7intel |
Really, it is just confusing.
Sometimes one thing is faster, sometimes other things are faster… Really hard to tell. It even varies a bit run-to-run on the same machine (especially for the fastest models). The results for GLM most closely mirror my initial hypothesis. But on the 11700, the Intel Conda channel is sometimes much slower than OpenBLAS, like on KNN, exactly where the 1135G7 is doing very well. This suggests there is a bug where the Intel channel is offloading to the detected GPU, even when the detected GPU is the 11700 iGPU which is way too tiny and actually slows things down. This rather ruins my AVX-2 vs AVX-512 comparison, as it’s also an iGPU comparison…
One thing I will say, the 1135g7 computer is drawing a lot less power than the 11700 for its results, I wish I had measured, but I will guesstimate at least 100 watts (one has a 90W power supply, the other a 550W power supply…). I also noticed differences in CPU utilization and clockspeed between the 11700 and 10700, with the 11700 actually often sustaining a lower clock speed 4.45 GHz which I believe was occurring with AVX-512 instructions, but also topping out at 5.0 GHz.
Complete Results Table:
| 11700intel | 11700openblas | amd4500Uopenblas | 10700intel | 10700openblas | 1135g7openblas | 1135g7intel_cold | 1135g7intel | FASTEST | Model Count | |
| AverageValueNaive | 38.13 | 113.65 | 88.21 | 38.73 | 119.94 | 118.38 | 35.57 | 36.44 | 1135g7intel_cold | 17 |
| DatepartRegression | 25.02 | 56.36 | 54.40 | 26.51 | 59.90 | 56.22 | 17.83 | 18.09 | 1135g7intel_cold | 12 |
| Ensemble | 360.10 | 346.94 | 661.28 | 441.63 | 421.08 | 478.05 | 538.87 | 563.92 | 11700openblas | 3 |
| GLM | 35.93 | 50.57 | 60.08 | 40.80 | 56.62 | 61.66 | 38.44 | 40.36 | 11700intel | 18 |
| GLS | 7.17 | 2.04 | 3.00 | 9.49 | 2.62 | 3.22 | 2.65 | 2.61 | 11700openblas | 12 |
| GluonTS | 912.40 | 904.62 | 1385.88 | 1096.02 | 1088.86 | 1050.25 | 1182.54 | 1203.21 | 11700openblas | 21 |
| LastValueNaive | 29.65 | 83.82 | 66.12 | 28.91 | 89.04 | 75.90 | 25.76 | 26.21 | 1135g7intel_cold | 16 |
| RollingRegression | 1452.90 | 688.60 | 1018.60 | 1617.19 | 874.20 | 1107.96 | 542.98 | 540.51 | 1135g7intel | 6 |
| SeasonalNaive | 157.38 | 197.47 | 169.16 | 179.47 | 225.42 | 166.25 | 141.76 | 143.46 | 1135g7intel_cold | 26 |
| VAR | 83.37 | 79.05 | 37.35 | 86.41 | 81.27 | 39.67 | 18.91 | 22.11 | 1135g7intel_cold | 12 |
| VECM | 15.24 | 13.40 | 8.90 | 16.36 | 8.61 | 15.51 | 6.82 | 7.06 | 1135g7intel_cold | 21 |
| WindowRegression | 1237.76 | 1527.80 | 1573.76 | 1454.73 | 1883.57 | 1720.25 | 1123.28 | 1147.04 | 1135g7intel_cold | 6 |
| ZeroesNaive | 30.97 | 86.91 | 85.06 | 30.79 | 92.54 | 87.17 | 27.97 | 28.90 | 1135g7intel_cold | 18 |
| Breakdown of Datepart/Rolling Regression Models: | Average | |||||||||
| Adaboost | 1.04 | 0.28 | 0.38 | 1.36 | 0.36 | 0.45 | 0.80 | 0.74 | 11700openblas | |
| BayesianRidge | 1093.58 | 590.06 | 967.83 | 1223.06 | 746.58 | 1054.49 | 493.89 | 492.18 | ` | |
| DecisionTree | 2.82 | 0.39 | 0.45 | 3.73 | 0.51 | 0.42 | 0.49 | 0.51 | 11700openblas | |
| ElasticNet | 0.61 | 0.07 | 0.08 | 0.81 | 0.09 | 0.07 | 0.10 | 0.09 | 11700openblas | |
| KNN | 359.99 | 98.67 | 50.96 | 394.99 | 127.80 | 53.67 | 49.35 | 48.56 | 1135g7intel | |
| MLP | 19.25 | 55.25 | 53.09 | 18.93 | 58.46 | 54.94 | 15.95 | 16.32 | 1135g7intel_cold | |
| SVM | 0.63 | 0.24 | 0.20 | 0.82 | 0.31 | 0.15 | 0.23 | 0.20 | 1135g7openblas | |
| Total Runtime (s) | 4386.04 | 4151.23 | 5211.82 | 5067.05 | 5003.67 | 4980.50 | 3703.40 | 3779.92 | 1135g7intel_cold |
If there are any takeaways I have:
- Make sure you configure your environment properly, use Intel Conda channel on Intel, and OpenBLAS on AMD, and probably if in doubt OpenBLAS (pip install) anywhere.
- I am excited for Intel Discrete GPUs as they promise to automatically accelerate numpy/scikit-learn without needing vendor-locked-in code like you have for Nvidia CuDF and related functions.
- AVX-512 does help, if not as much as the GPU does.